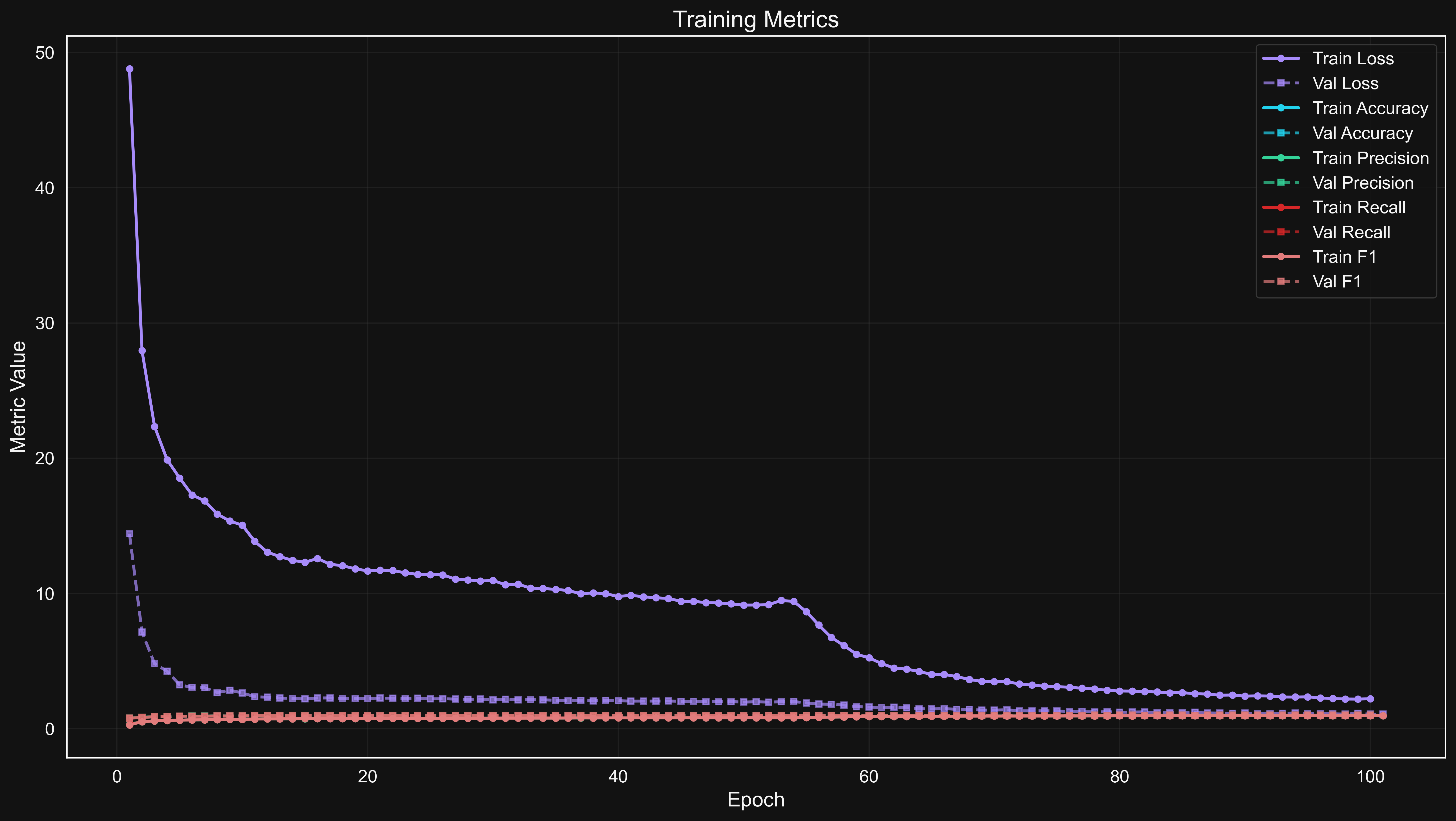
The training history shows convergence patterns for loss and accuracy metrics over time.
This report presents a rigorous evaluation of the optimized cbam_only_resnet18 v2 architecture for plant disease diagnosis across 39 categories. This version achieves comparable accuracy with significantly reduced training time.
The training data consists of a comprehensive plant disease dataset with the following characteristics:
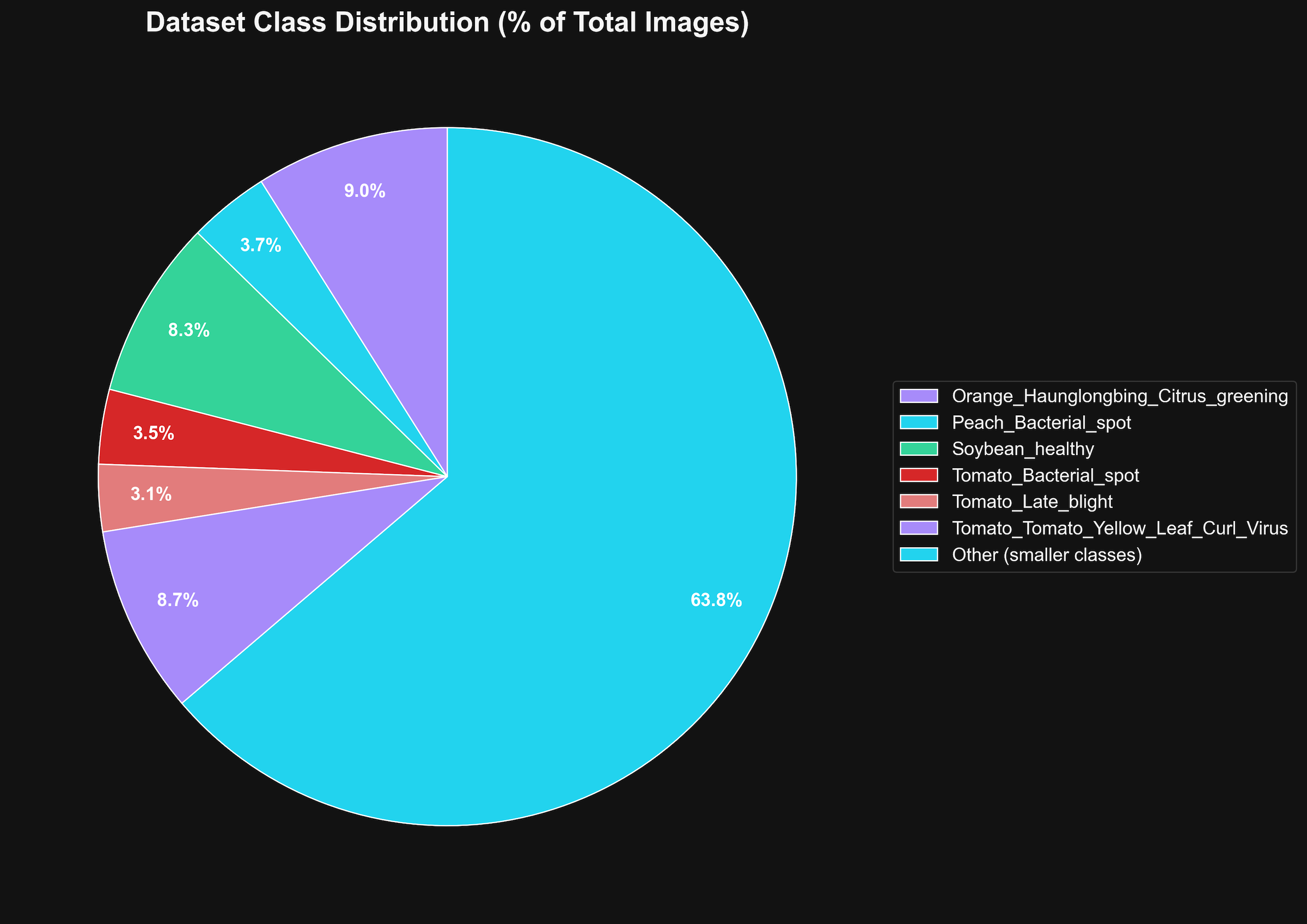
The dataset exhibits class imbalance with the largest classes being:
Many classes contain approximately 1,000 images each (1.63% of the dataset). This imbalance was addressed during training through weighted sampling and data augmentation techniques.
To prepare the dataset for optimal training, the following preprocessing steps were implemented:
A comprehensive augmentation pipeline was implemented using Albumentations:
The v2 model architecture combines a ResNet18 backbone with optimized Convolutional Block Attention Modules (CBAM) and improved training strategy:
The v2 model demonstrates significant efficiency gains over v1:
Analysis of the training process revealed interesting patterns:
The v2 model's efficiency makes it particularly well-suited for:
Detailed configuration of the cbam_only_resnet18 v2 model and training process.
The training history shows convergence patterns for loss and accuracy metrics over time.
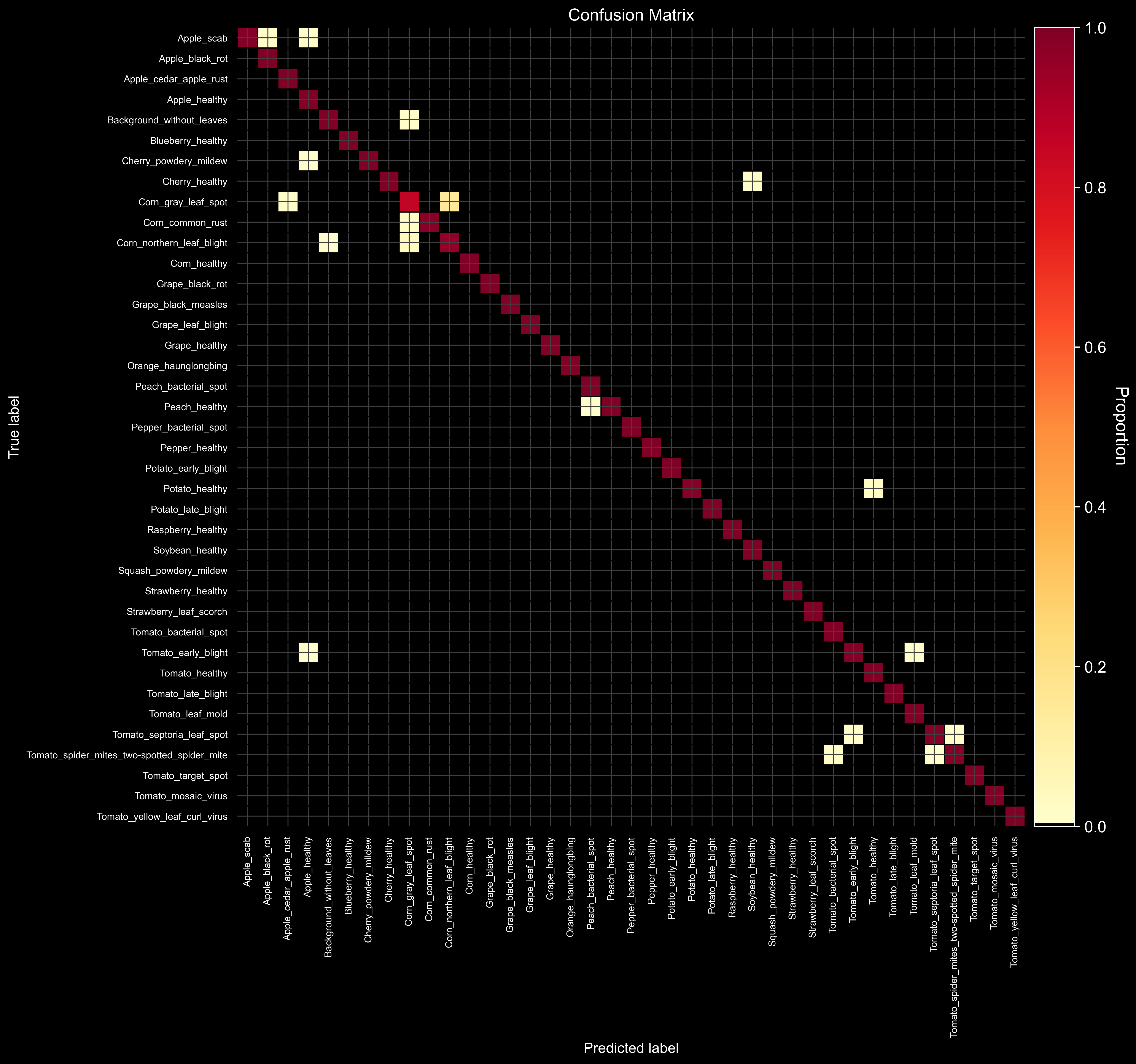
The confusion matrix visualizes classification performance across 39 classes.
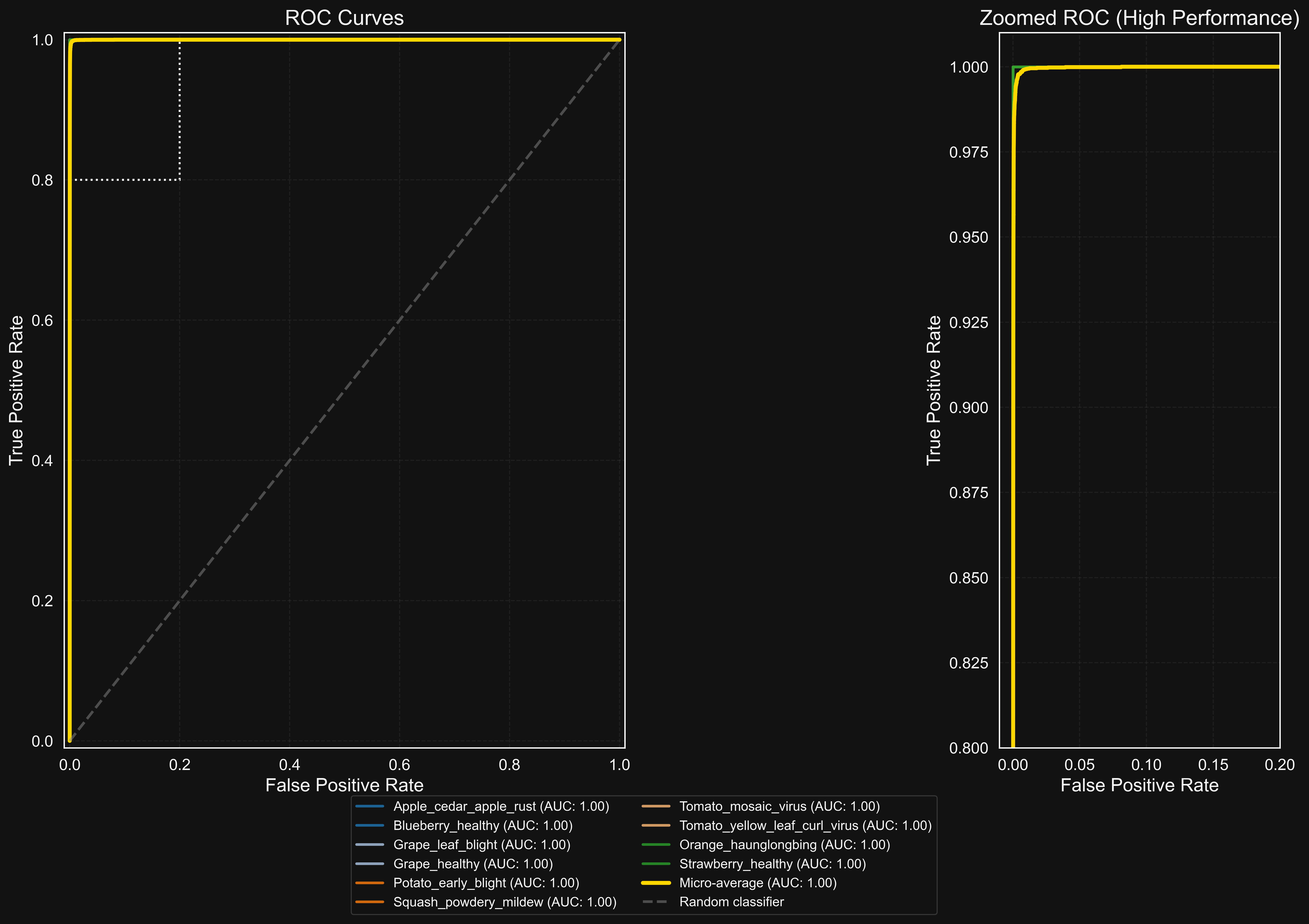
ROC curves showing the trade-off between true positive rate and false positive rate for each class.
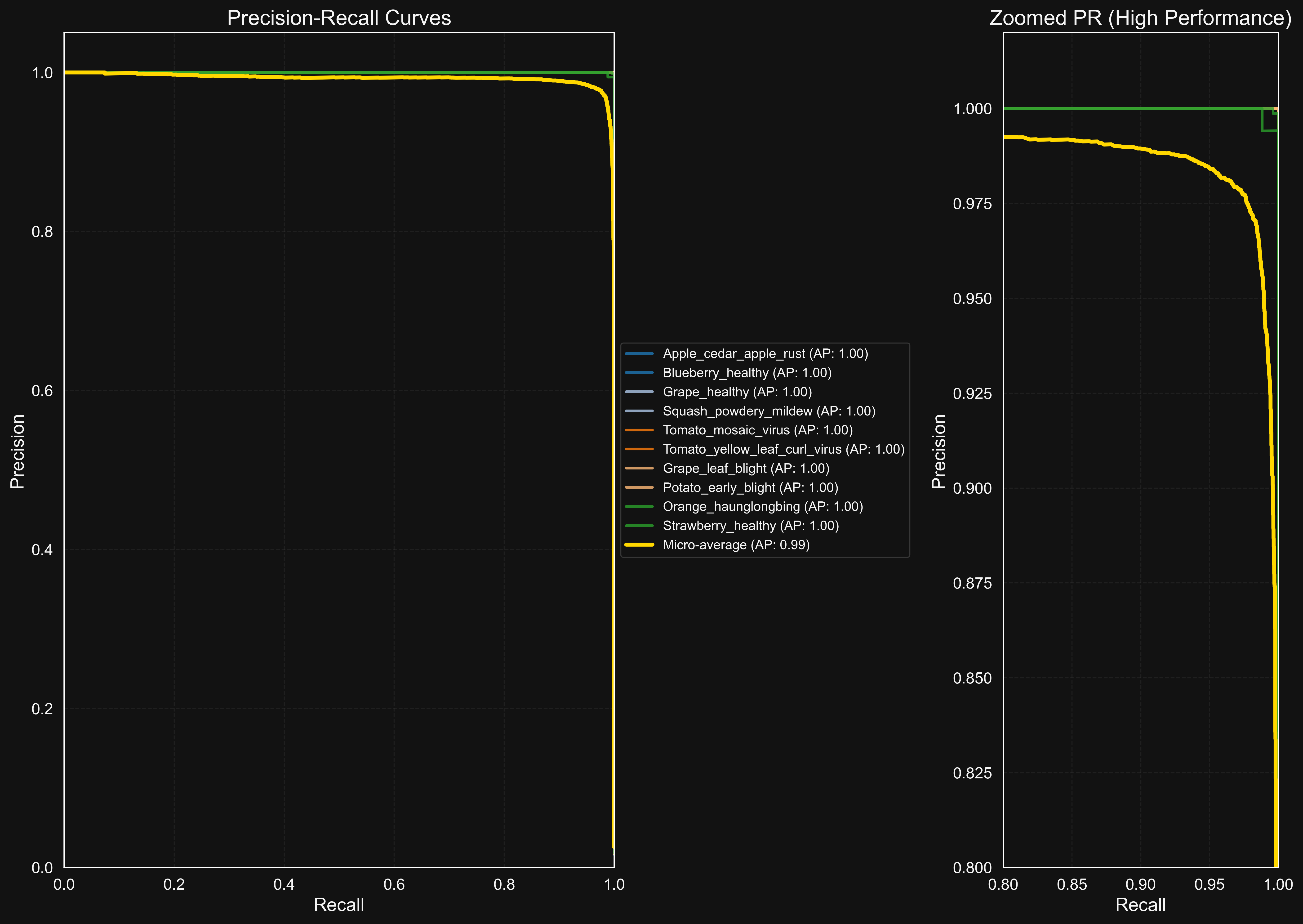
Precision-recall curves showing the trade-off between precision and recall for each class.
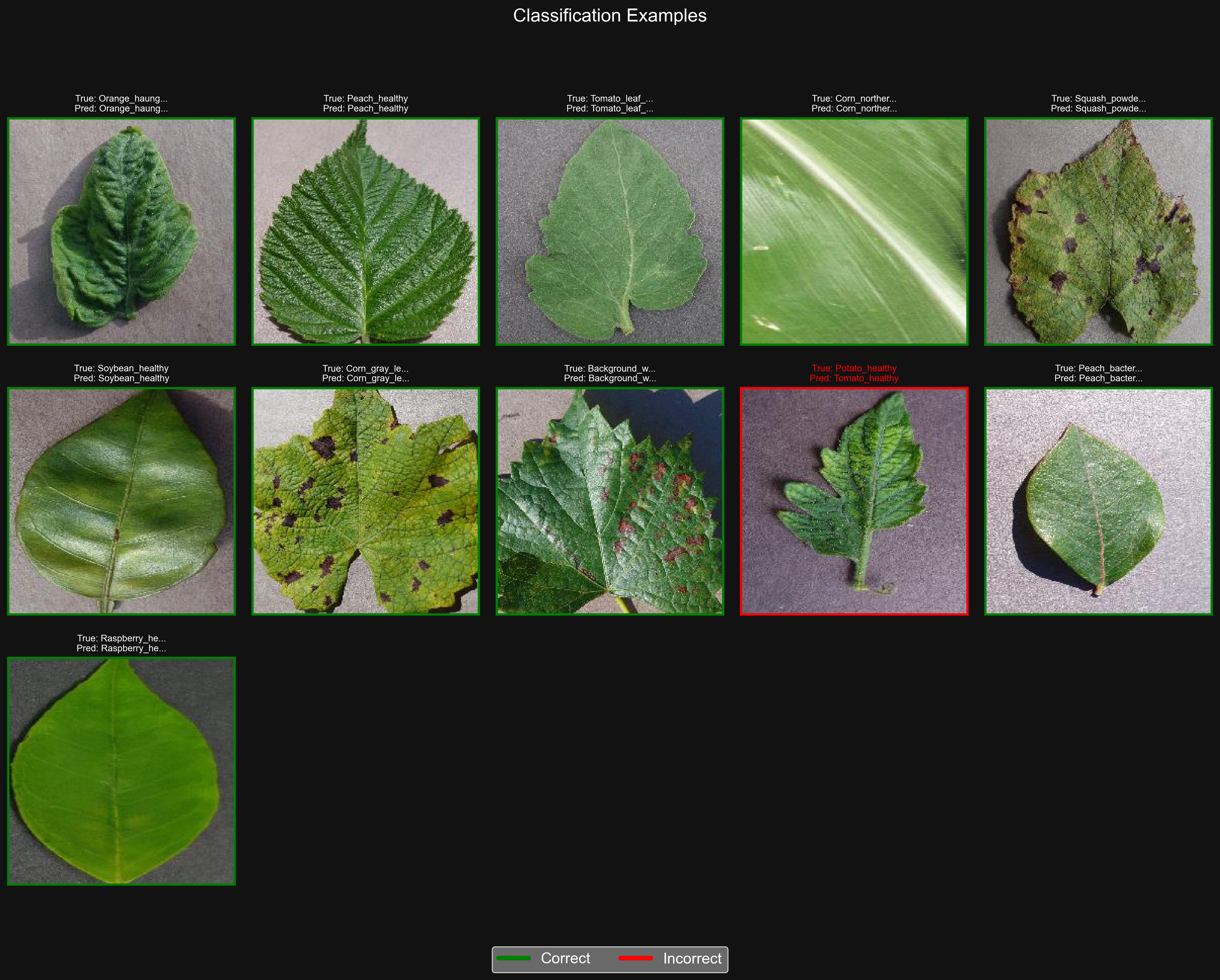
Examples of model predictions on test images, with correct predictions in green and incorrect ones in red.
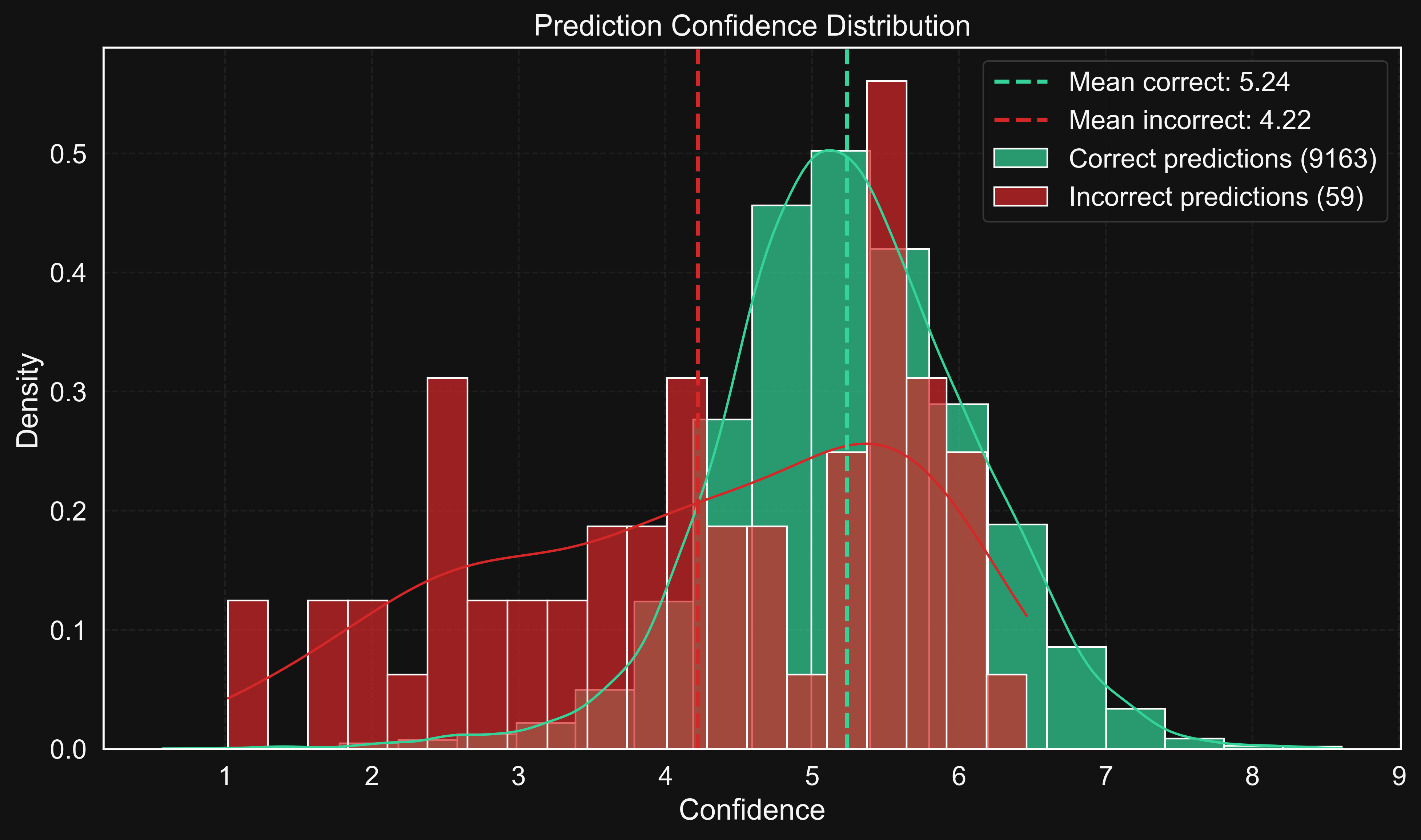
Histogram showing the distribution of prediction confidences across all test samples. The model shows a low average confidence of N/A.
Performance metrics across all 39 classes.
The cbam_only_resnet18 v2 model achieved an overall accuracy of 96.71% on the challenging 39-class plant disease classification task, with significantly improved training efficiency. This demonstrates the model's robust performance despite a substantially reduced training schedule.
The cbam_only_resnet18 v2 model demonstrates that optimized training strategies can dramatically reduce training time while maintaining excellent classification performance. With only a 0.75% reduction in accuracy compared to v1, but 67% less training time, this model represents an excellent trade-off between performance and efficiency for plant disease diagnosis applications.